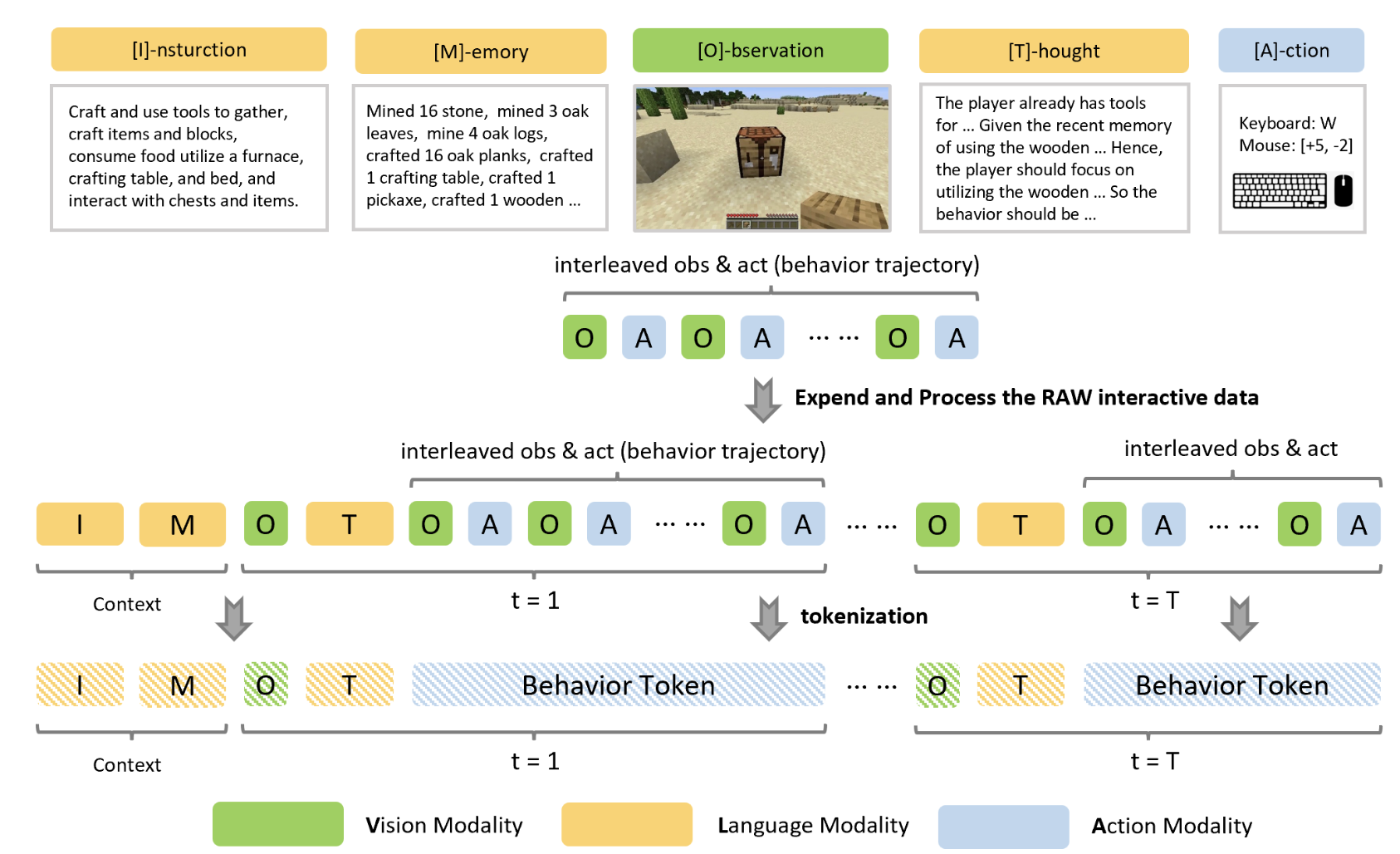
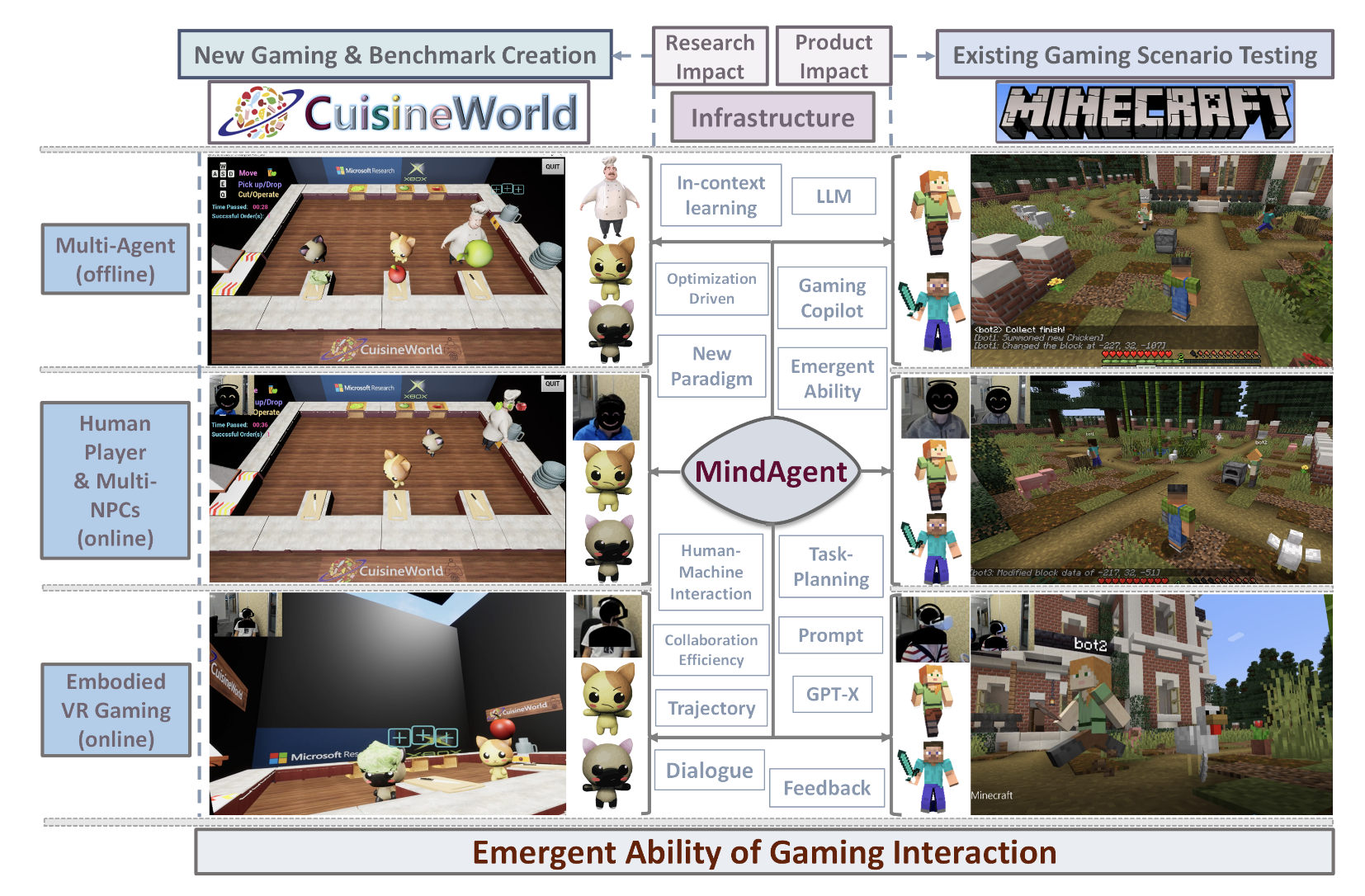
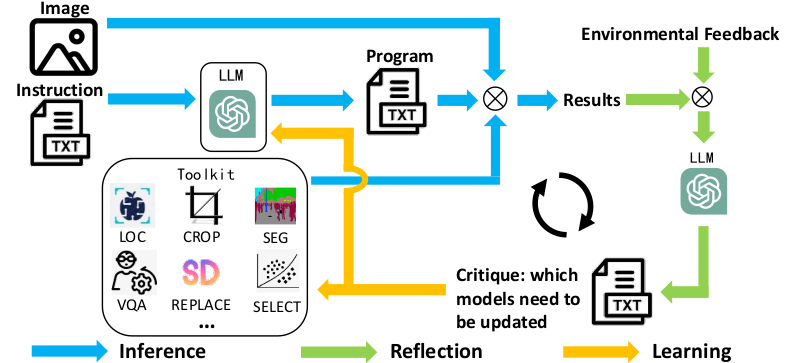
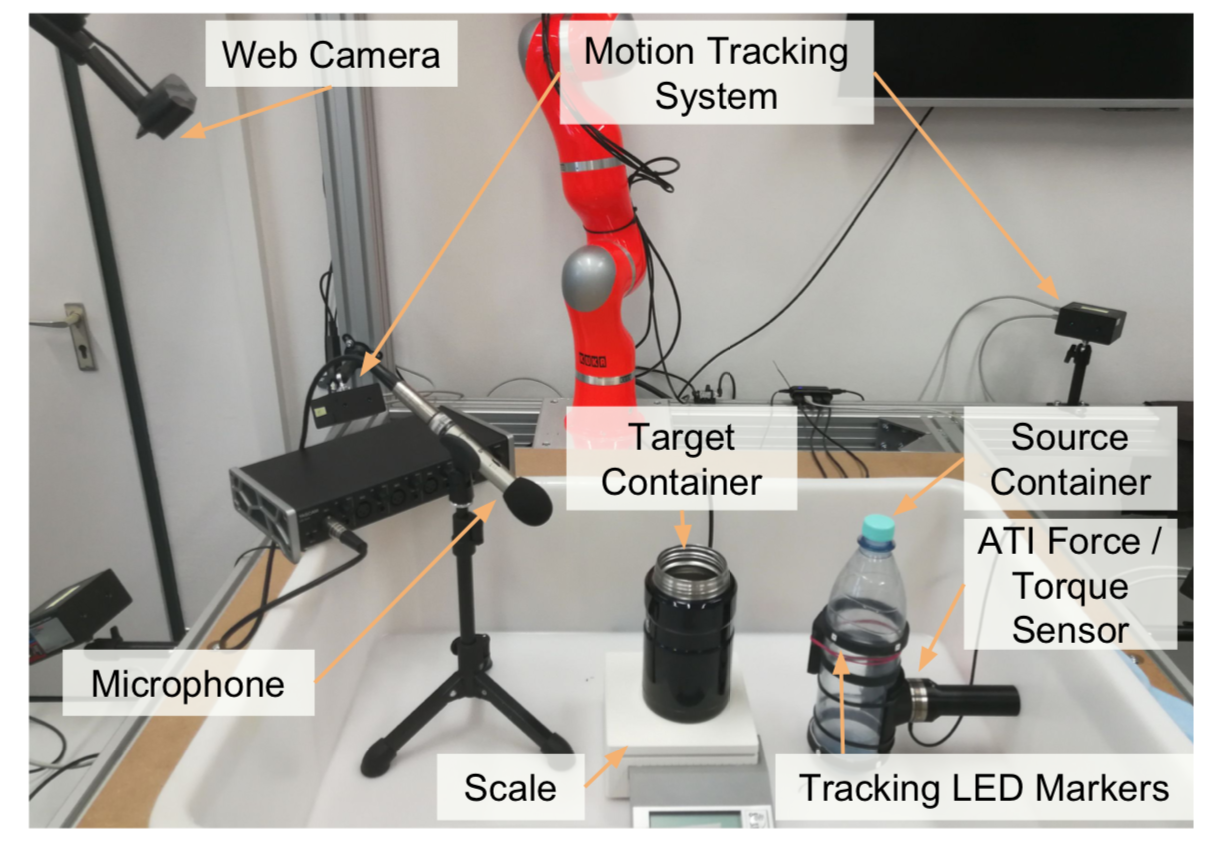
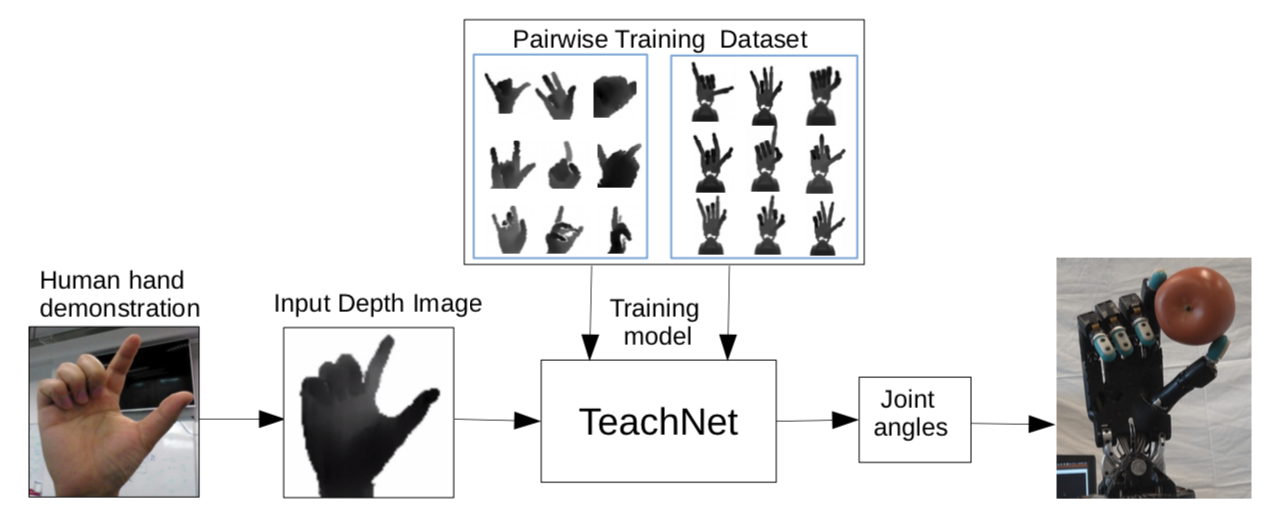
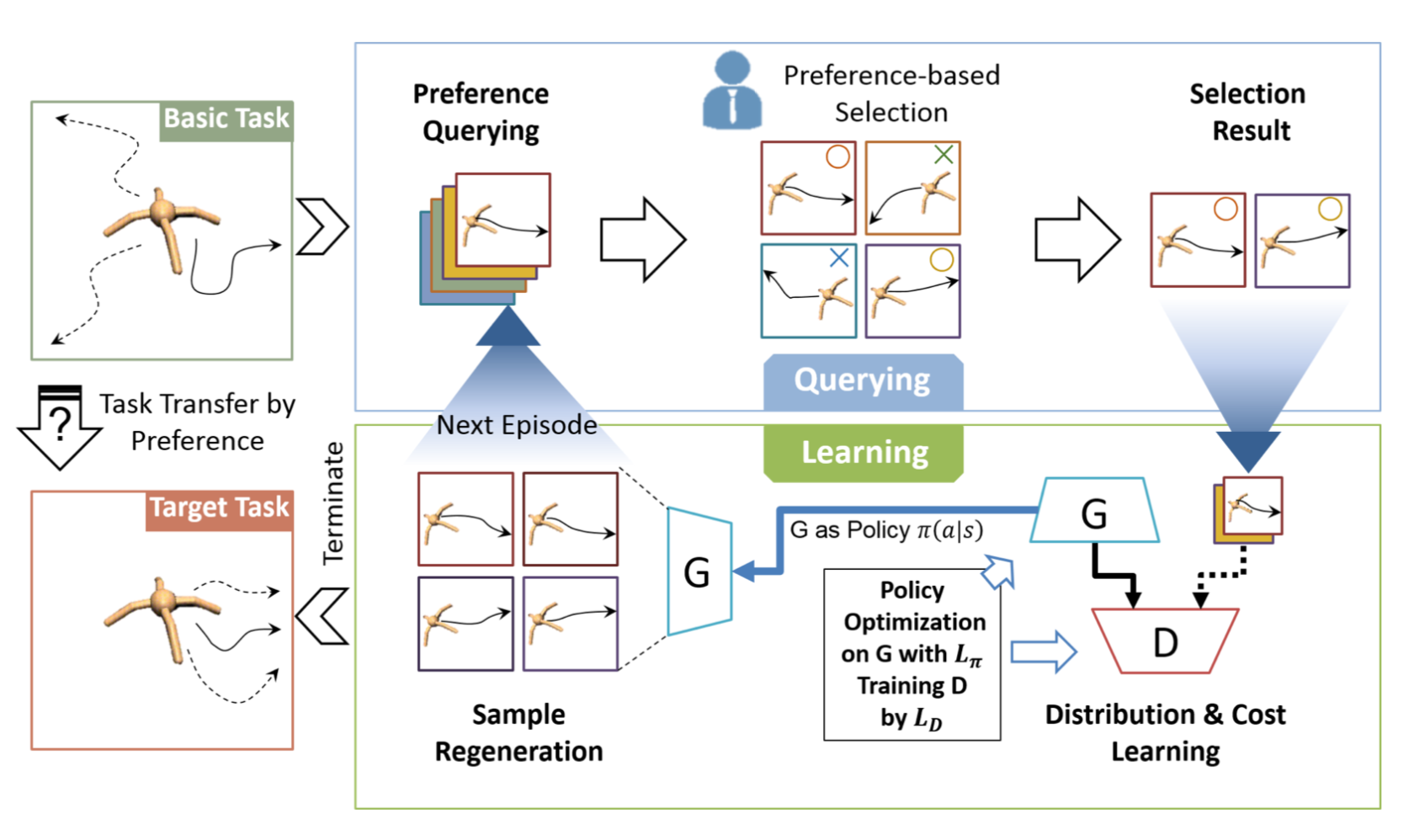
Welcome to my academic homepage. I am a machine learning researcher. I received my Ph.D. in Computer Science at University of California, Los Angeles (UCLA) . I went to Tsinghua University for undergraduate study in Computer Science.
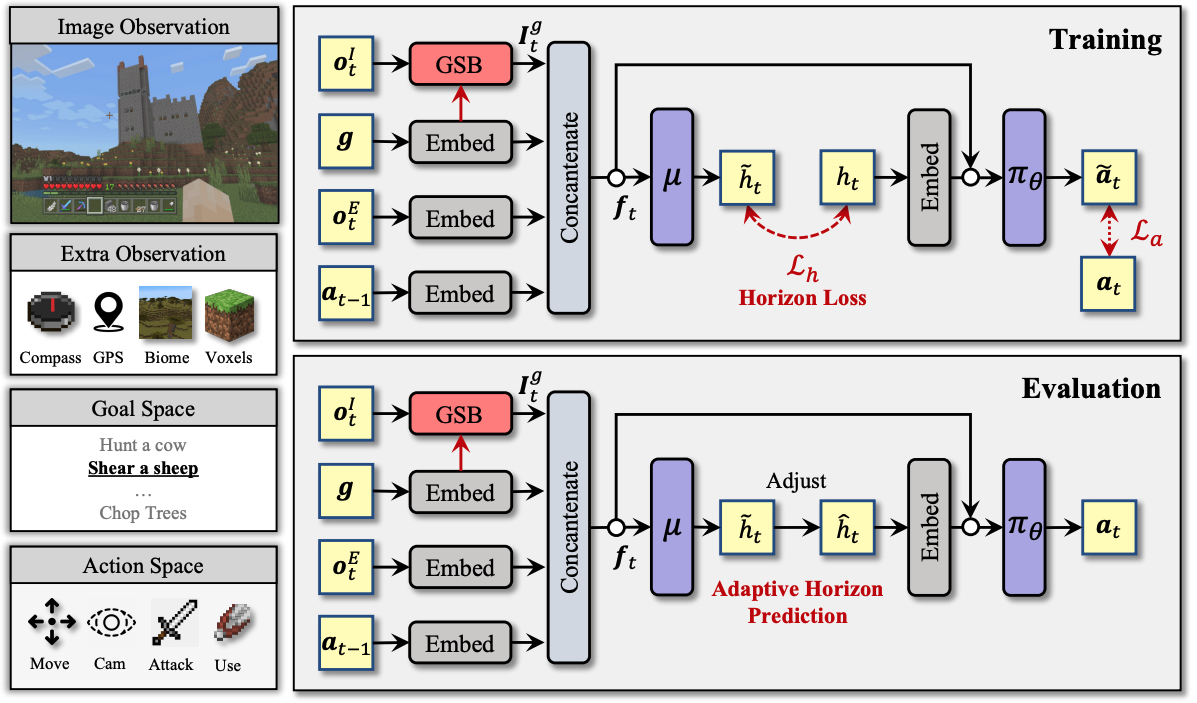
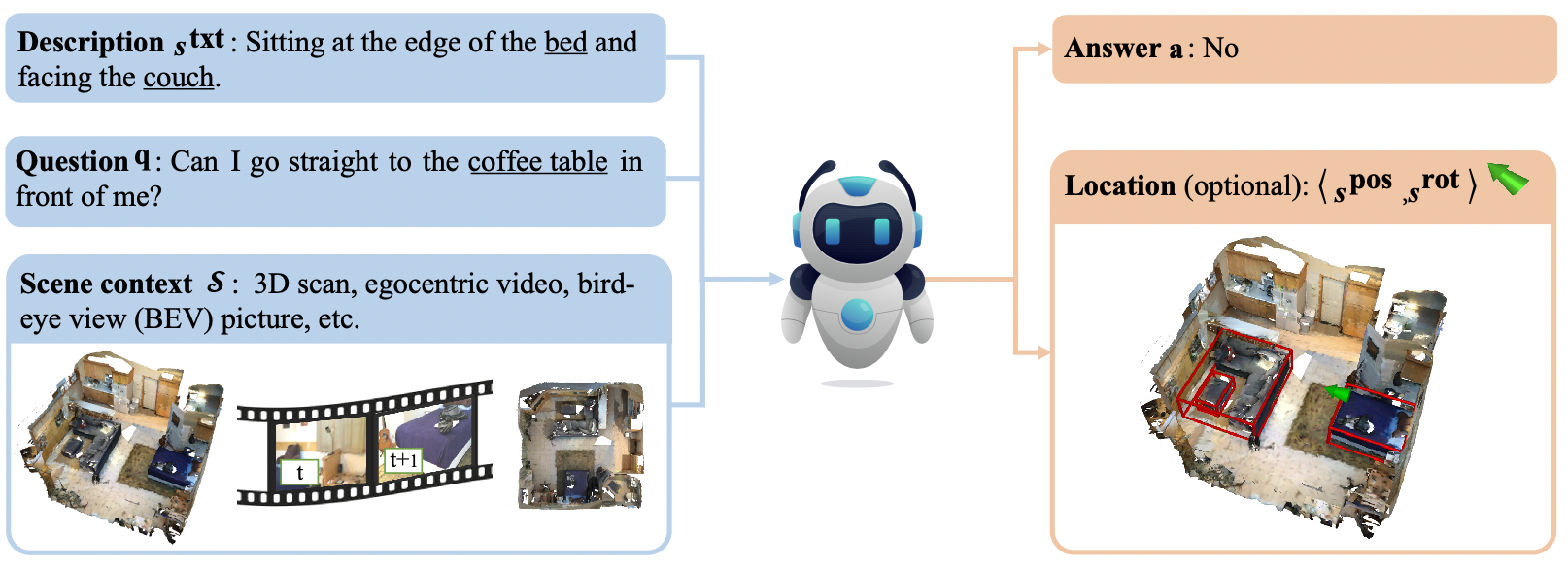
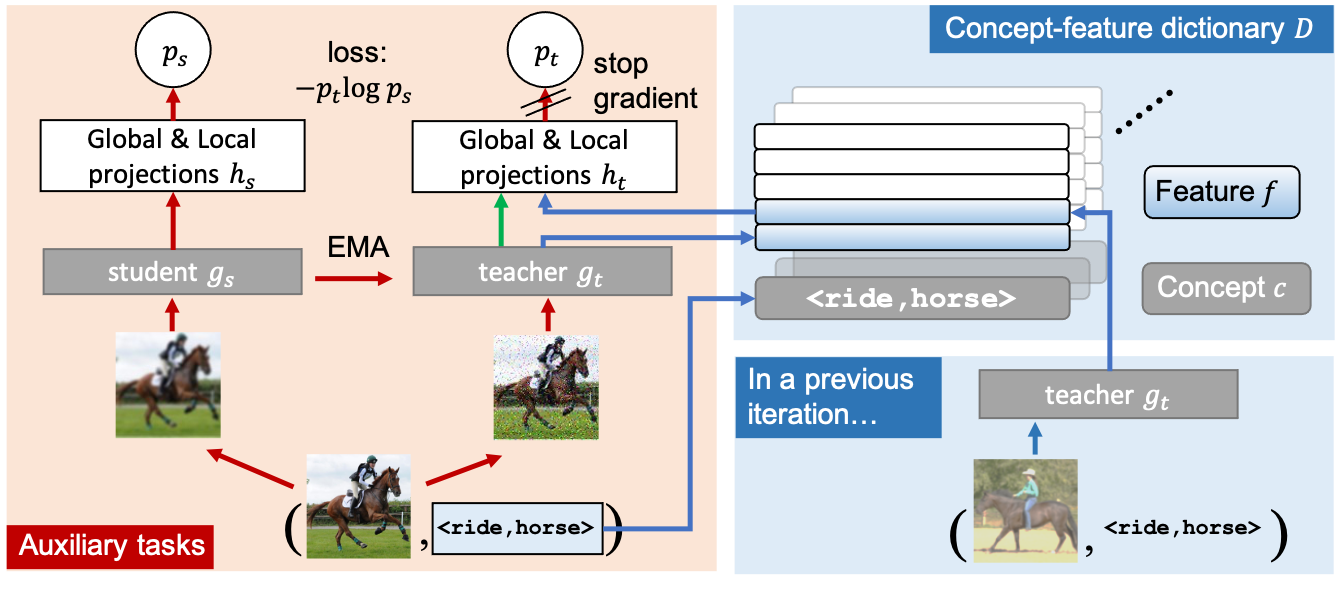
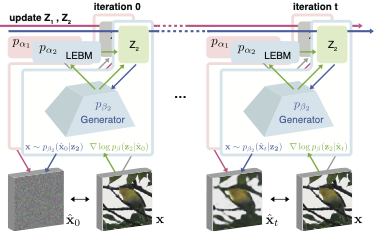
I work on multimodal learning for understanding, reasoning and skill learning. In particular, I'm interested in building models/agents that can learn from 2D/3D vision and text data, and perform a wide range of reasoning and embodied control tasks. Some of my research keywords can be found below:
- Multimodal learning: Vision and language, Visual reasoning, 3D vision, Generalist models
- Representation learning: Zero-shot and few-shot learning, Generative model
- Embodied agents: Reinforcement learning and imitation, Robotics, Sensor fusion
Email: jeasinema [at] gmail [dot] com / Google Scholar / LinkedIn